百倍算力效率的背后:揭示国产推理芯片的系统级突围路径
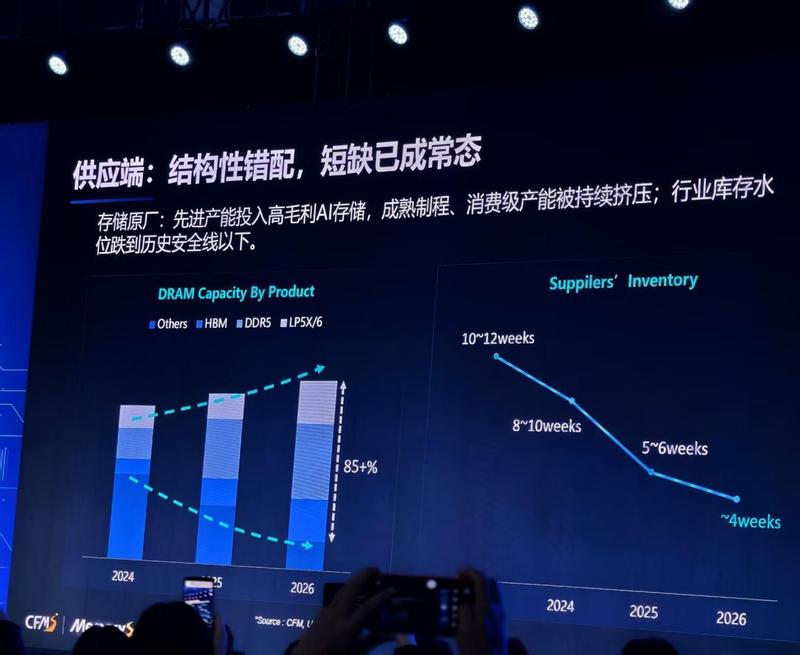
回溯2025年,彼时大模型领域正经历着从“参数竞赛”向“应用实效”的深刻转型。作为长期关注半导体产业的观察者,我清晰地记得当时行业内部对于“算力通胀”的隐忧。彼时,主流市场依然沉迷于通过堆砌高端显卡来提升模型性能,但随着推理需求的爆发性增长,单纯的硬件堆叠模式逐渐显露出疲态。这种疲态不仅体现在昂贵的采购成本上,更体现在极低的能源利用率和复杂的运维难度中。
关键节点出现在行业对“算力访存比”的重新定义上。当计算速度远超数据读取速度时,性能瓶颈便产生了。这不仅是一个技术难题,更是一次行业范式的转移。正如英伟达在VeraRubin平台中所展示的那样,系统级协同设计成为了破局的关键。国产芯片厂商曦望在这一阶段的策略调整,精准地踩中了时代脉搏:将80%的战略资源投入推理领域,并致力于将百万token成本降低至分级水平,这不仅是商业策略,更是对摩尔定律在推理场景下的一次有力回应。
系统协同:构建算力新范式的核心逻辑
在分析国产算力的深层逻辑时,我们必须剥离掉浮华的参数对比,回归到芯片架构的本质。目前的困境在于,传统的训推一体架构在面对高频、实时交互的智能体(Agent)场景时,往往显得力不从心。高昂的成本与不稳定的供应,迫使大模型厂商开始寻求替代方案,即通过软硬件的深度耦合,摆脱对单一生态的过度依赖。
这种系统协同的本质,在于打破“计算”与“存储”之间的物理隔阂。通过自研芯片与模型框架、算子库的深度适配,国产算力厂商正在尝试构建一种新的计算范式。这种范式不仅追求单芯片的算力峰值,更追求在实际应用场景下的有效利用率。当算力不再是单纯的资源消耗品,而是通过系统级优化转化为生产力时,国产算力的竞争力便得以真正体现。
从应用视角出发的算力架构重构
对于正在探索AI转型的企业而言,理解这一范式转移至关重要。未来的算力竞争,不再取决于谁拥有最多的芯片,而取决于谁能更高效地利用这些资源。企业在进行算力部署时,应优先考虑那些具备“系统级协同设计”能力的解决方案。这要求厂商具备极强的全链路技术整合能力,能够将模型架构的特性与硬件底层的访存逻辑进行无缝对接,从而在有限的硬件资源下,释放出最大的推理吞吐量,确保AI应用的长期可持续性。